

Extracting the National Health Interview Survey Linked Mortality File (NHIS-LMF)
Jessica Bishop-RoyseAt the 2024 Fall meeting of IAPHS in Minneapolis, Andrew Fenelon and Julia Drew presented a pre-conference workshop entitled “Studying Mortality using Harmonized National Health Interview Survey Linked Mortality File Data (NHIS-LMF) from IPUMS.” For those who don’t know, the NHIS Linked Mortality File data can be accessed through IPUMS website.
The NHIS Linked Mortality File (LMF) provides users with information from the National Death Index (NDI) for eligible NHIS sample members. The LMF linkage is periodically refreshed and the current version links information from the 1986-2018 NHIS to information on the fact, timing, and cause of death from the NDI through December 31, 2019. The National Health Interview Survey (NHIS) has been collected by the National Center for Health Statistics (NCHS) from 1963 to present and includes information on the health, health care access, and health behaviors of the civilian, non-institutionalized U.S. population. The NDI is the most complete source of mortality information in the U.S., containing more than 115 million death records. Briefly, it includes:
- Death records from 1979 to the present, for the 50 states, the District of Columbia, New York City, Puerto Rico, and the U.S. Virgin Islands
- Some years of records for Guam, American Samoa, and the Northern Mariana Islands
- Out-of-country deaths of U.S. military personnel (since 1979)
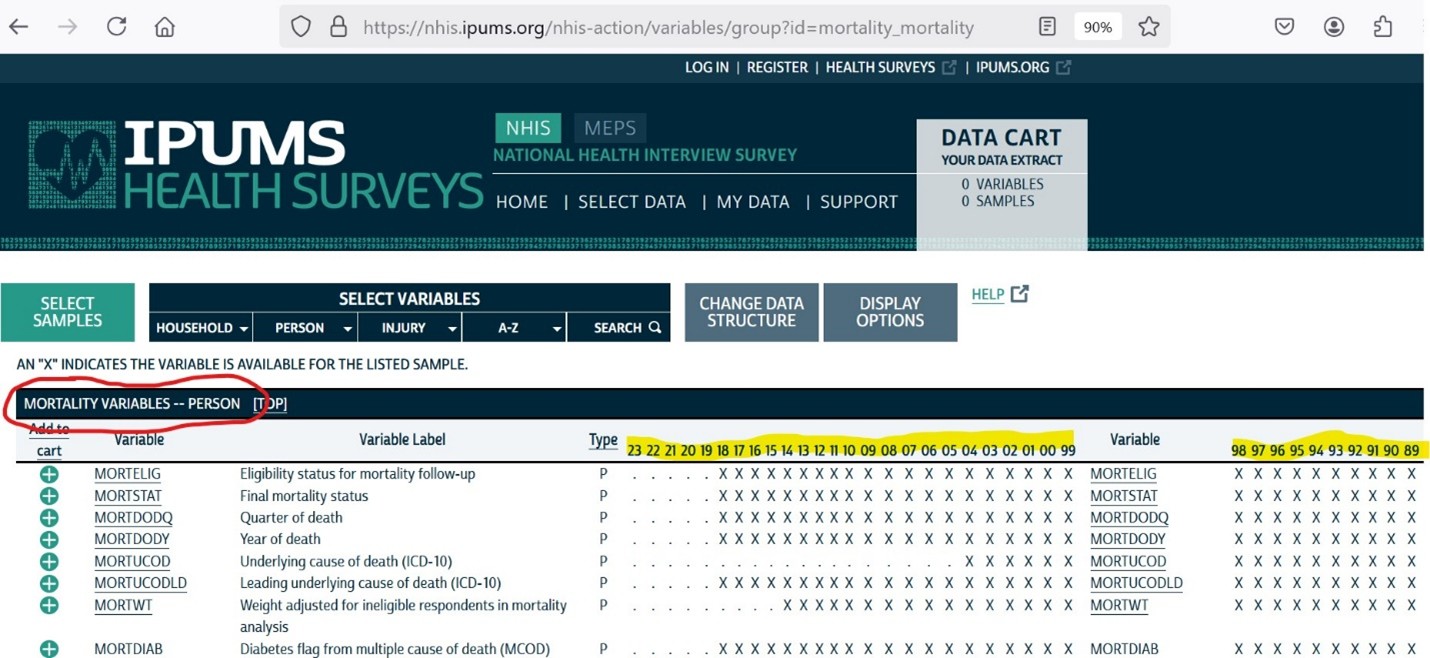
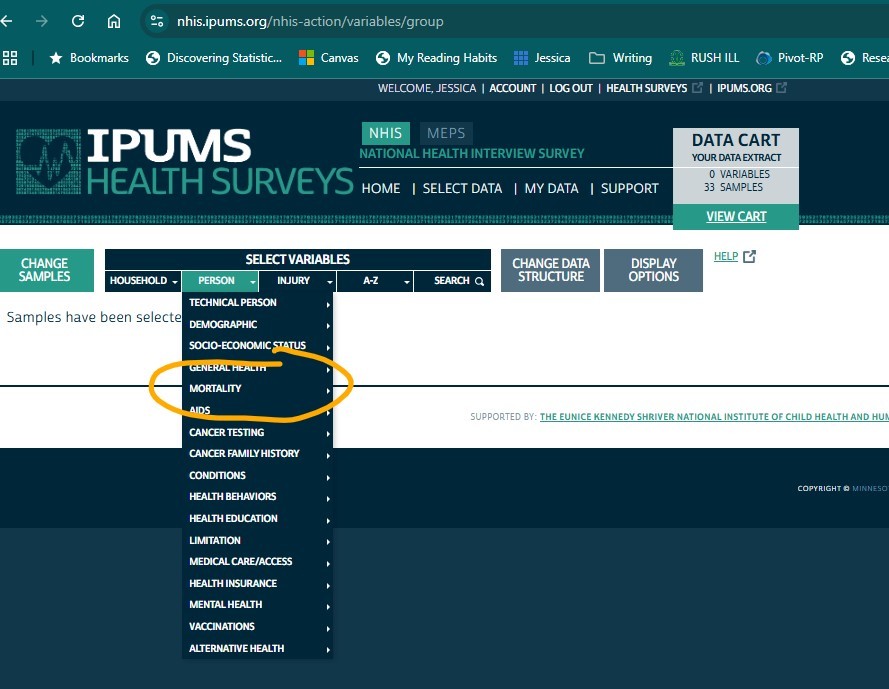
The IPUMS Health Surveys have harmonized the public use version of the LMF data, allowing users to create custom NHIS-LMF data extracts for analysis. Users can select preferred variables from the IPUMS user interface, including mortality indicators such as mortality status, year and quarter of death, and several broad categories of cause of death. For more detailed information on cause of death, researchers must request access to the restricted versions of the data provided by NCHS.
The sample size for the NHIS is large, ranging from 60,000-100,000 (most years are in the 80,000-90,000 range) participants surveyed each year of data collection. With such a large sample, NHIS-LMF makes it possible to detect relatively small differences in mortality risk among subpopulations The NHIS-LMF data have been used to study topics such as the immigrant paradox in mortality, “deaths of despair,” and the contribution of specific health behaviors to sex differences in mortality.
In their pre-conference workshop, Fenelon and Drew showed how to access the NHIS LMF data through IPUMS NHIS, and introduced variables that were available for analysis. Basically, it was enough information to get attendees intrigued and started, with the idea that interested attendees would have enough to warrant further action when they returned home. To save time, Fenelon and Drew prepared data extracts for workshop participants for analysis in person, but also included instructions for doing so. They provide general instructions on how to make an extract from IPUMS extract and get started working with the data (scroll down to the “Health Surveys” row and select the exercises that correspond (scroll down to the “Health Surveys” row and select the exercises that correspond to the stats package of your choice).
In my basic exploration of the NHIS and IPUMS webpages, I found a user guide that provides some useful resources for researchers looking to use this data source. There is functionality to analyze data online using UC Berkeley’s Computer Assisted Survey Methods Program. The process could not be easier for researchers wanting to build a data extract so that they can analyze data on their own machines. Researchers wanting to get this data will need to sign up for an account and login.
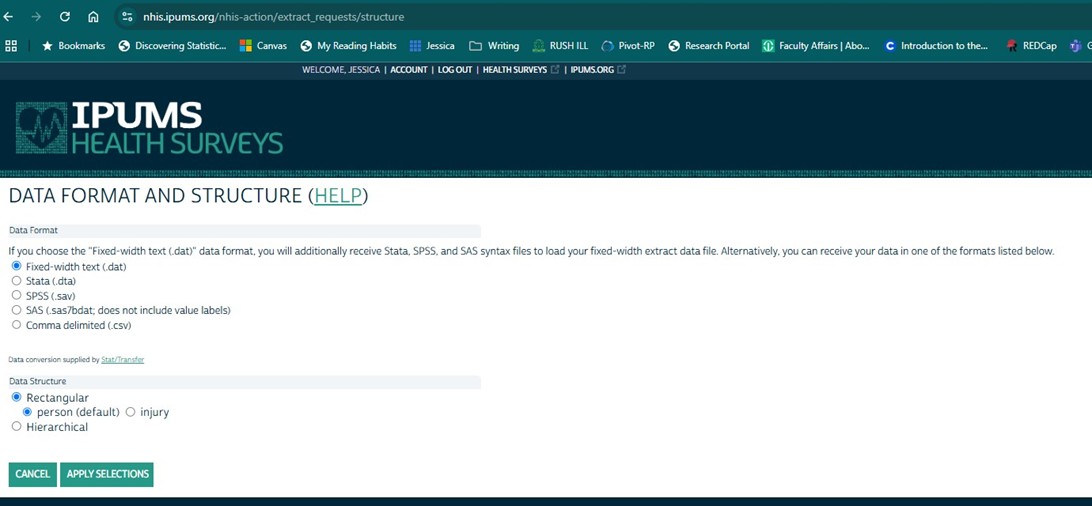
There are several cool features about downloading data from the NHIS IPUMS website. First, previous extracts can be revised. So, if you’re working on data analysis and realize that you need to add a variable or a year of data, it’s easy enough to go back into the data to revise the request — meaning you don’t have to make an entirely new request. Second, Stat/Transfer provides data conversion — so if you want to have .dta files for use in Stata, you can. But you can also have .sav files for use in SPSS or even just plain .csv files for use in R (or something else). Third, as part of the account creation process — you have to enter an email address. And you get a notification email when the extract is ready for download.
The pre-conference workshop presented by Fenelon and Drew included some basic commands for summary analysis in Stata, as well as some additional resources and notes.

")

")
All comments will be reviewed and posted if substantive and of general interest to IAPHS readers.